![[Python] 开源:小红书无需登录直接下载视频、图片、API版本|Aae_Source](https://www.aae.ink/wp-content/uploads/2023/11/b45fc0663f20231113152707-800x412.png)


软件介绍:
其实小红书下载图片挺简单的,视频也还好,把自用的代码分享出来,大家一起讨论,共同进步。想要什么功能,自己改源码就可以。
软件截图:
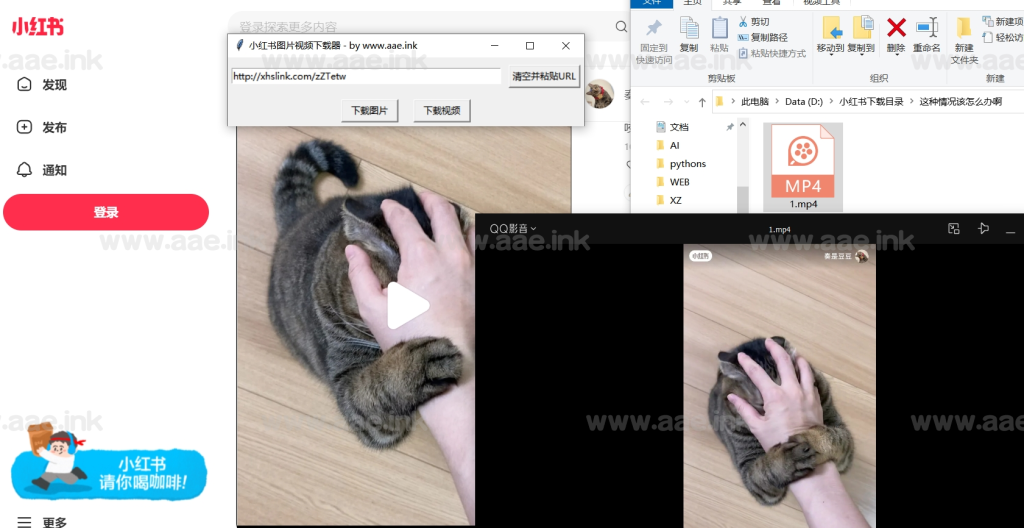
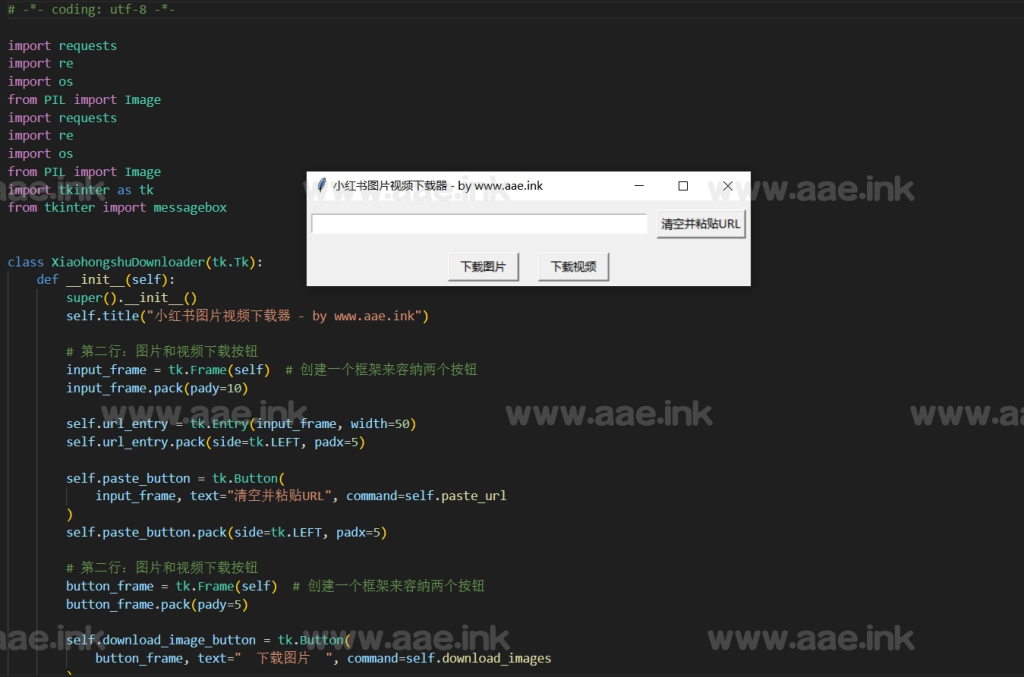
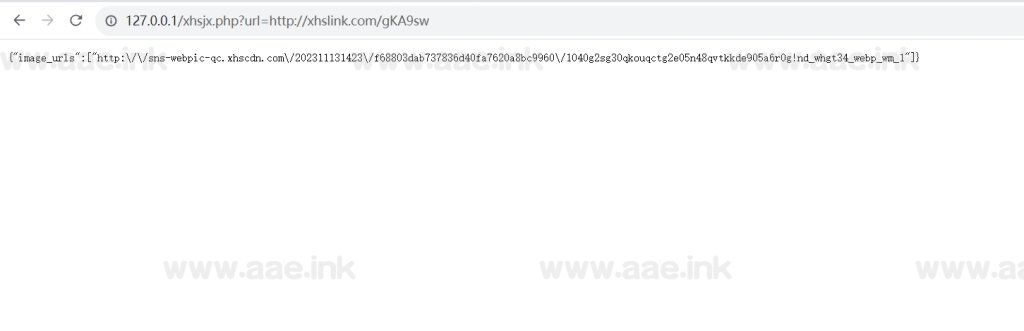
源码下载地址:
Python版本:
# -*- coding: utf-8 -*-
import requests
import re
import os
# from PIL import Image
# def webp_to_jpeg(webp_path):
# # 获取文件名和目录
# file_dir, file_name = os.path.split(webp_path)
# # 检查文件扩展名是否为.webp
# if not file_name.lower().endswith(".webp"):
# print("输入的文件不是WebP格式!")
# return
# # 构建JPEG保存路径
# jpeg_path = os.path.join(file_dir, os.path.splitext(file_name)[0] + ".jpg")
# try:
# # 打开WebP图片
# webp_image = Image.open(webp_path)
# # 将WebP图片保存为JPEG格式
# jpeg_image = webp_image.convert("RGB")
# jpeg_image.save(jpeg_path, "JPEG")
# print(f"成功将{file_name}转换为JPEG格式,保存为{os.path.basename(jpeg_path)}")
# os.remove(webp_path)
# except Exception as e:
# print(f"转换过程中出现错误:{str(e)}")
def get_html(url):
url = url.split("?")[0]
headers = {
"authority": "www.xiaohongshu.com",
"cache-control": "max-age=0",
"sec-ch-ua": '"Chromium";v="21", " Not;A Brand";v="99"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-language": "zh-CN,zh;q=0.9",
}
response = requests.get(url, headers=headers)
return response.text
def json_content(html):
rule = r"<script>window\.__INITIAL_STATE__=(.*?)</script>"
js = re.search(rule, html, re.I)
if js:
content = js.group(1)
return content
else:
return None
def get_img_urls(html):
"""获取图片地址"""
urls = re.findall(r'url":"(http://[^\":\{\}\[\]]*?wm_1)"', html)
return set(urls)
def get_video_urls(html):
"""获取视频地址"""
urls = re.findall(r'masterUrl":"(http://[^\":\{\}\[\]]*?.mp4)"', html)
return set(urls)
def fix_folder_name(folder_name):
"""
去除不能作为文件夹名的字符
"""
# 定义要替换的非法字符正则表达式
illegal_chars_regex = r'[\\/:\*\?"<>\|]'
correct_name = re.sub(illegal_chars_regex, "", folder_name)
return correct_name
def get_note_title(html):
title = re.findall(r'noteId.*?type.*?title":"(.*?)"', html)
if title:
return fix_folder_name(title[0])
else:
return "未知标题"
def download(url, save_path):
response = requests.get(url, stream=True)
if response.status_code == 200:
with open(save_path, "wb") as f:
for chunk in response.iter_content(1024):
f.write(chunk)
print("下载完成!")
else:
print("下载失败!")
def download_img_urls(urls):
for n, url in enumerate(urls, 1):
print(url)
# 设置下载目录
save_path = f"D:/小红书下载目录/{title}"
if not os.path.exists(save_path):
os.makedirs(save_path)
webp_img = os.path.join(f"{save_path}/{n}.webp")
download(url, webp_img)
# webp_to_jpeg(webp_img)
os.popen(f"explorer {os.path.realpath(save_path)}")
def download_video_urls(urls):
for n, url in enumerate(urls, 1):
print(url)
# 设置下载目录
save_path = f"D:/小红书下载目录/{title}"
if not os.path.exists(save_path):
os.makedirs(save_path)
mp4 = os.path.join(f"{save_path}/{n}.mp4")
download(url, mp4)
os.popen(f"explorer {os.path.realpath(save_path)}")
if __name__ == "__main__":
# 图片 https://www.xiaohongshu.com/explore/639aa24f000000001f001b8f
# 视频 https://www.xiaohongshu.com/explore/64578c160000000013030eeb
url = input("请输入笔记URL:")
select = input("请输入数字要下载的类型: 1 图片 2 视频\n直接回车则下载图片:")
# main(url)
html = get_html(url)
js = json_content(html)
js = js.replace(r"\u002F", r"/")
title = get_note_title(js)
if not select.strip() or select.strip() == "1":
all_urls = get_img_urls(js)
print(all_urls)
download_img_urls(all_urls)
elif select.strip() == "2":
all_urls = get_video_urls(js)
print(all_urls)
download_video_urls(all_urls)
os.system("pause")PHP接口版本:
<?php
function get_html($url) {
$headers = array(
"authority" => "www.xiaohongshu.com",
"cache-control" => "max-age=0",
"sec-ch-ua" => '"Chromium";v="21", " Not;A Brand";v="99"',
"sec-ch-ua-mobile" => "?0",
"sec-ch-ua-platform" => '"Windows"',
"upgrade-insecure-requests" => "1",
"user-agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
"accept" => "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-fetch-site" => "same-origin",
"sec-fetch-mode" => "navigate",
"sec-fetch-user" => "?1",
"sec-fetch-dest" => "document",
"accept-language" => "zh-CN,zh;q=0.9",
);
$options = array(
'http' => array(
'header' => implode("\r\n", array_map(
function ($v, $k) {
return $k . ':' . $v;
},
$headers,
array_keys($headers)
)),
),
);
$context = stream_context_create($options);
$response = file_get_contents($url, false, $context);
return $response;
}
function json_content($html) {
$rule = '/<script>window\.__INITIAL_STATE__=(.*?)<\/script>/i';
preg_match($rule, $html, $matches);
if ($matches) {
$content = $matches[1];
return $content;
} else {
return null;
}
}
function get_image_urls($url) {
$html = get_html($url);
$js = json_content($html);
$js = str_replace("\\u002F", "/", $js);
preg_match_all('/"url":"(http:\/\/[^":\{\}\[\]]*?wm_1)"/', $js, $all_urls);
return array('image_urls' => $all_urls[1]);
}
if ($_SERVER['REQUEST_METHOD'] === 'GET') {
$url = $_GET['url'];
if ($url) {
$result = get_image_urls($url);
header('Content-Type: application/json');
echo json_encode($result);
} else {
header('Content-Type: application/json');
echo json_encode(array('error' => 'Missing URL parameter'));
}
}
?>Python接口版本:
from flask import Flask, request, jsonify
import requests
import re
app = Flask(__name__)
@app.route('/')
def index():
url = request.args.get('url')
if url:
result = get_image_urls(url)
return jsonify(result)
else:
return jsonify({'error': 'Missing URL parameter'})
def get_html(url):
headers = {
"authority": "www.xiaohongshu.com",
"cache-control": "max-age=0",
"sec-ch-ua": '"Chromium";v="21", " Not;A Brand";v="99"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-language": "zh-CN,zh;q=0.9",
}
response = requests.get(url, headers=headers)
return response.text
def json_content(html):
rule = r"<script>window\.__INITIAL_STATE__=(.*?)</script>"
js = re.search(rule, html, re.I)
if js:
content = js.group(1)
return content
else:
return None
def get_image_urls(url):
html = get_html(url)
js = json_content(html)
js = js.replace(r"\u002F", r"/")
all_urls = re.findall(r'url":"(http://[^\":\{\}\[\]]*?wm_1)"', js)
return {'image_urls': all_urls}
if __name__ == "__main__":
app.run(debug=True)
本站所有资源下载后请自行杀毒!
所有资源站长均在虚拟机内完成测试!
免责声明:
1、本站所发布的一切资源仅限用于学习和研究目的;
2、不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。
3、本站信息来自网络,版权争议与本站无关。
4、您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容。
5、如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
Centos虚拟机镜像下载地址:https://www.aae.ink/35201.html
Window虚拟机镜像下载地址:https://www.aae.ink/35207.html
本站仅用于网络资源分享,本站所有资源均来自于互联网收集,并不对内容完整性负责,本站所有资源,只提供给爱好研究者使用切勿用于任何商业用途,本站不对任何人的商业行为负责。
© 版权声明
THE END
![[一键安装] 【转载】原神3.4真端服务端+源码+配套客户端+详尽说明+GM工具+源码说明文件|Aae_Source](https://www.aae.ink/wp-content/uploads/2023/08/61c86a488f104207.png)






![[一键安装] 崩坏3V1.5版本一键端启动端分享+一键代理+免虚拟机一键启动+女武神ID+详细指令+极简一键修改|Aae_Source](https://www.aae.ink/wp-content/uploads/2023/09/94d6cdea56150351-1024x490.png)








请登录后查看评论内容